
I must confess, when I first heard the term ‘Shadow Engineering’ I called bullshit. It sounded like yet another acronym, coined by a security vendor to put FUD into readers, and then magically sell them a solution to the problem. Yes I am cynical, but any followers of Crash Override know that we are almost anti-marketing and anti-sales. We ‘market like we want to be marketed to’, meaning our goal is to provide our opinion. It's the same for sales, ‘sell like you want to be sold to’. Go to our demo page, https://crashoverride.com/vip-tour and you will see ‘We’re not going to bend your ear or twist your arm to sell you a solution you don’t need. Instead, we’ll take 30 minutes to demonstrate what Crash Override can do and how it solves DevOps challenges.’ We live by this mantra, it's called brand integrity.
So this is an opinion piece and a convenient truth for us.
First lets refresh our memory about some principles of DevOps. This is from Google Gemini AI.
- Automation: Automating repetitive tasks like code builds, testing, and deployments can significantly reduce errors and speed up the development process. Infrastructure as Code (IaC) allows for automated provisioning and management of infrastructure.
- Continuous Integration and Continuous Delivery (CI/CD): CI involves frequently integrating code changes into a shared repository, enabling early detection of integration issues. CD automates the process of building, testing, and deploying code to production, allowing for faster and more frequent releases.
- Continuous Improvement: DevOps promotes a culture of continuous learning and improvement, where teams are always looking for ways to optimize their processes and tools.
I would summarize the relevant bits to this article as, ‘ automate the crap out of everything using the CI/CD as the checkpoint, and constantly try better tools’.
Now for a definition of a shadow system as defined by Wikipedia in 2007, ‘a term used in information services for any application relied upon for business processes that is not under the jurisdiction of a centralized information systems department. That is, the information systems department did not create it, was not aware of it, and does not support it’.
I would summarize this as anything that hasn’t been approved and isn’t under control of the team that owns, for the sake of a better word, engineering.
Anyone that has worked with me over the years in the capacity of an engineering leader, knows my approach has always been that developers should have the best tools they want, and that are available to them. My corp card has been in and out of systems so much, that at this point, it's basically a tradition.
What I have learned from our customers, and is obvious in hindsight, is that this causes no end of headaches, and that the headache is two sides of the same coin for both security and software engineering.
I will use the example of a container registry, but it would equally have been source code management, CI/CD, development languages and frameworks, cloud infrastructure, infrastructure as code tools, secret storage, and the list goes on.
When you have a centralized container registry, software engineering teams benefit though:
- Information sharing among engineers leads to better collaboration and quicker problem-solving. Browsing a directory of pre-built images, means people know what's available off-the-shelf, and that they don’t need to do it themselves.
- Significantly improved supportability. This container has a version of this tech that makes production barf, let’s all fix it so everyone doesn't waste time fixing the same problem and our customers suffer.
- Best practices, ensuring consistent quality and reducing errors, such as semantic version tagging images so we are all talking about the same thing.
- Streamlined workflows and improved collaboration, means less wasted time and faster time to market. Spend time designing and coding solutions to customer problems, or maintain infrastructure and tools.
- And all of this of course, and perhaps the most important thing, is this leads to reduced costs of duplicated and wasted time, as well as software licenses by consolidating resources and leveraging economies of scale.
The benefits are clear, but it also goes without saying these are only true if centralized resources are available, and I do believe that a large portion of shadow engineering is the result of it not being true, and or the way it is managed is ‘onerous’, AKA crap.
Now for the other side of the same coin. Security wants to reduce risk, and that means making sure the right controls are in the right place. Authentication, authorization, network controls, it's the age old things, plus system specific configuration of course. The key here is also the age old and probably overused phrase, you can’t manage what you don't know about.
Security also wants to manage vulnerabilities. The old school approach has been to scan images with a vulnerability scanner, but that's just whack–mole. You find the same issues over and over again, demand the same problems are fixed and waste time and money. The new approach, well hardly new but the one that has had the resurgence of popularity is to use gold images like Chainguard. Provide a set of images that are known to be free of CVE’s and then everyone drinks from clean water. Find an issue and fix it once and everyone's a winner.
So why am I writing about this? That is the convenient truth for Crash Override. One of the use cases that came out of our design partner program was that it turned out we were incredibly good at finding shadow engineering, everything from rogue systems to legacy languages and banned libraries, running in production.
First we have the centralized cloud infra and code infrastructure captured in the platform, linked and maintained automatically in the catalog feature.
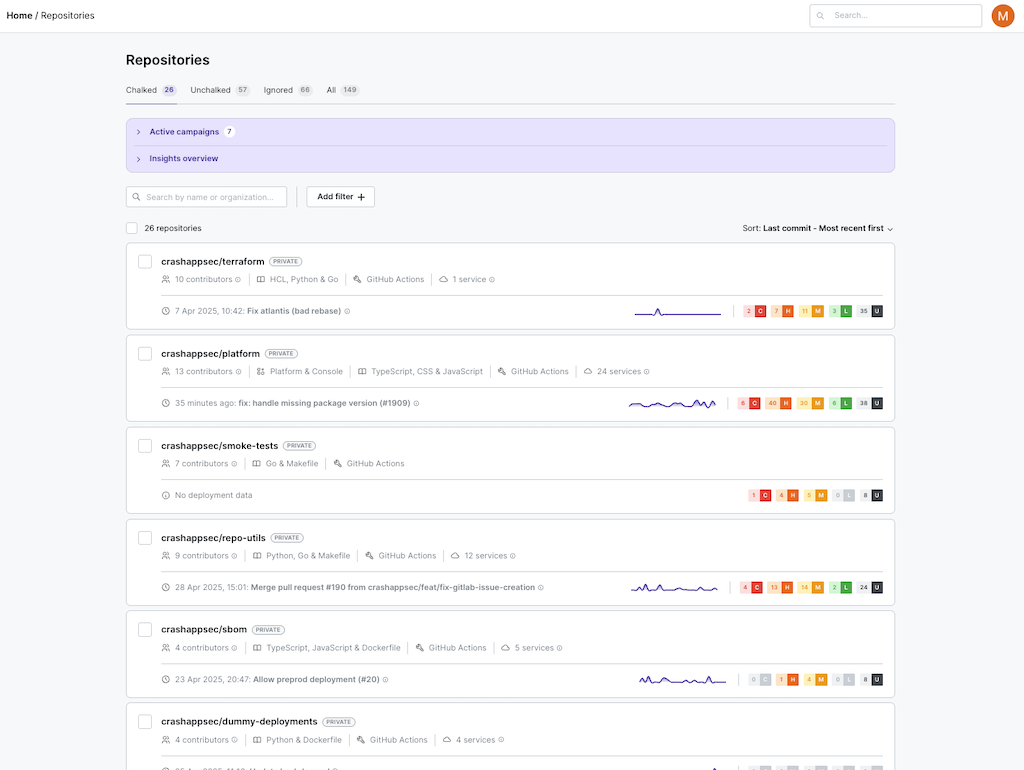
Then when the builds go through Chalk (now at https://chalkproject.io/), we capture an incredible amount of information. We know the container registries used, the container ID, processes run when the container is built… we have it all, hundreds of bits of meta-data from inside the build, not outside looking in. If you want to visibility, start by looking in the right place.
Then every time a build happens we know everything about everything.
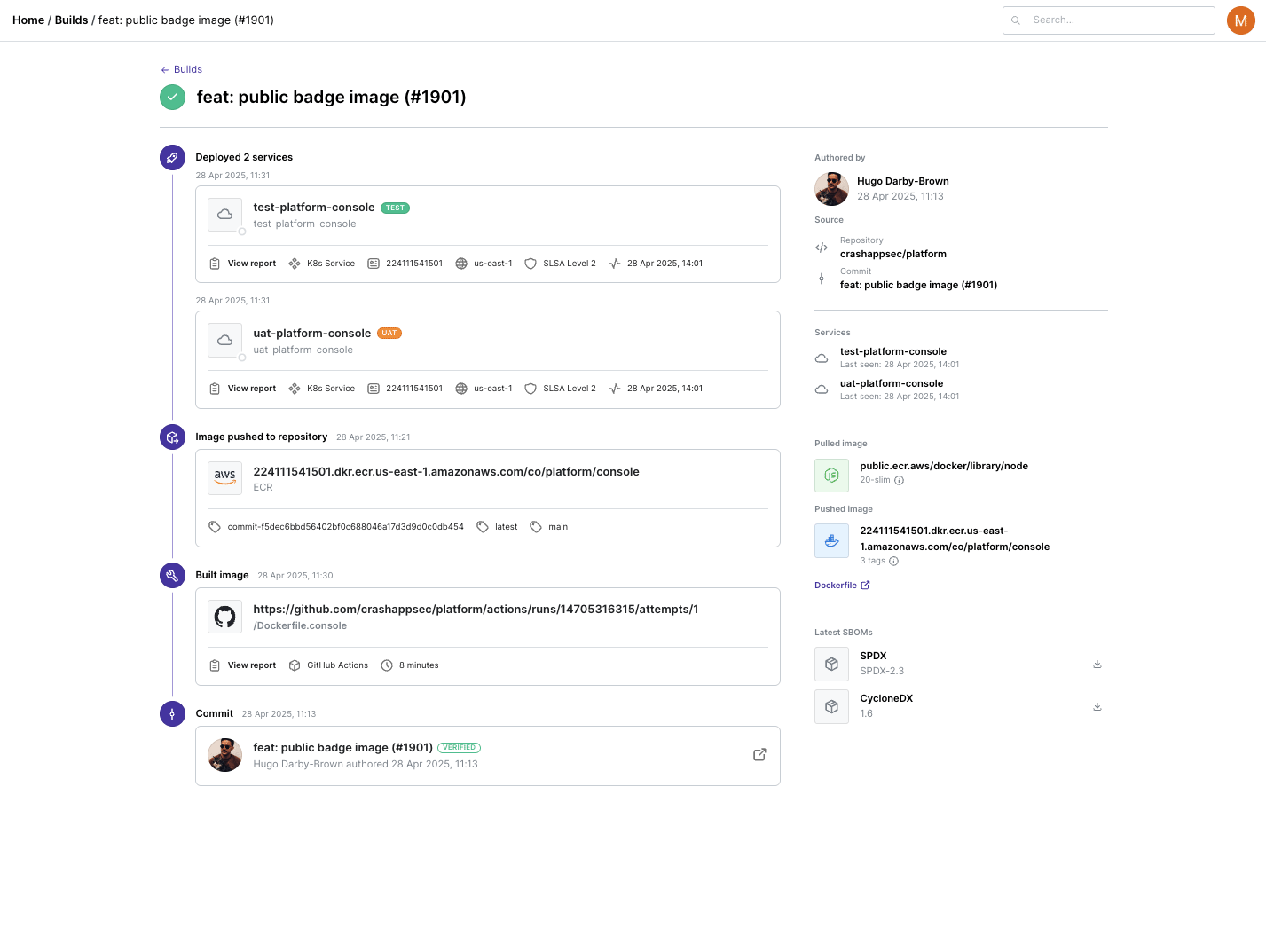
And that really does means everything.
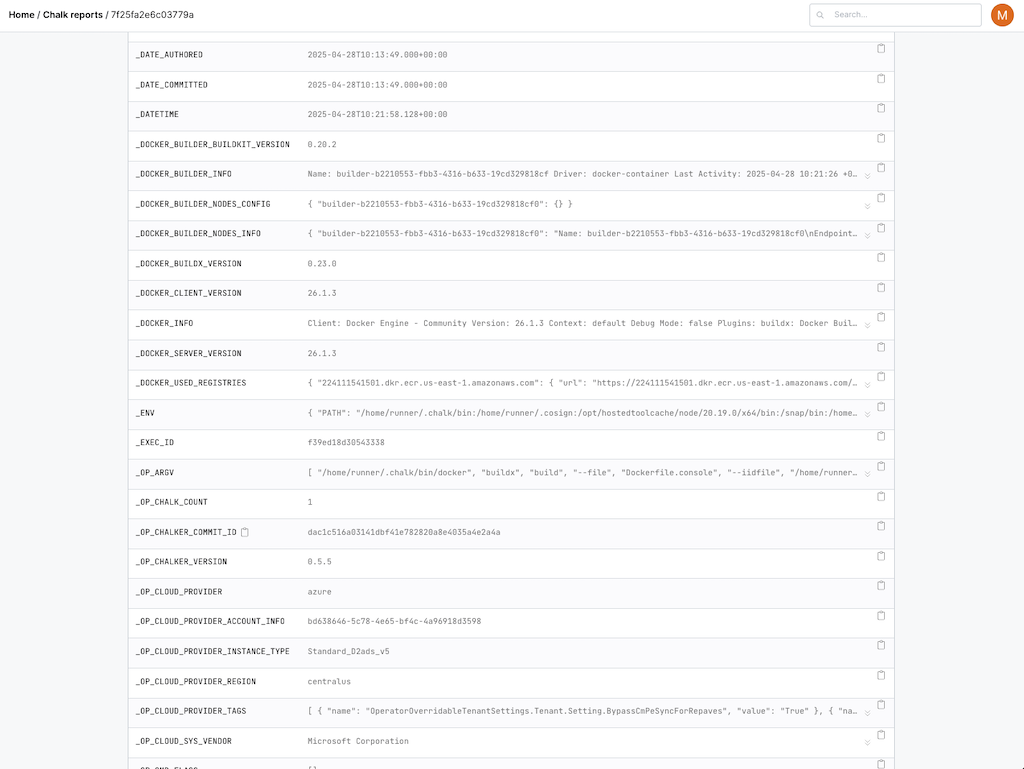
We then use all of that info, to determine what is approved and what's shadow engineering.
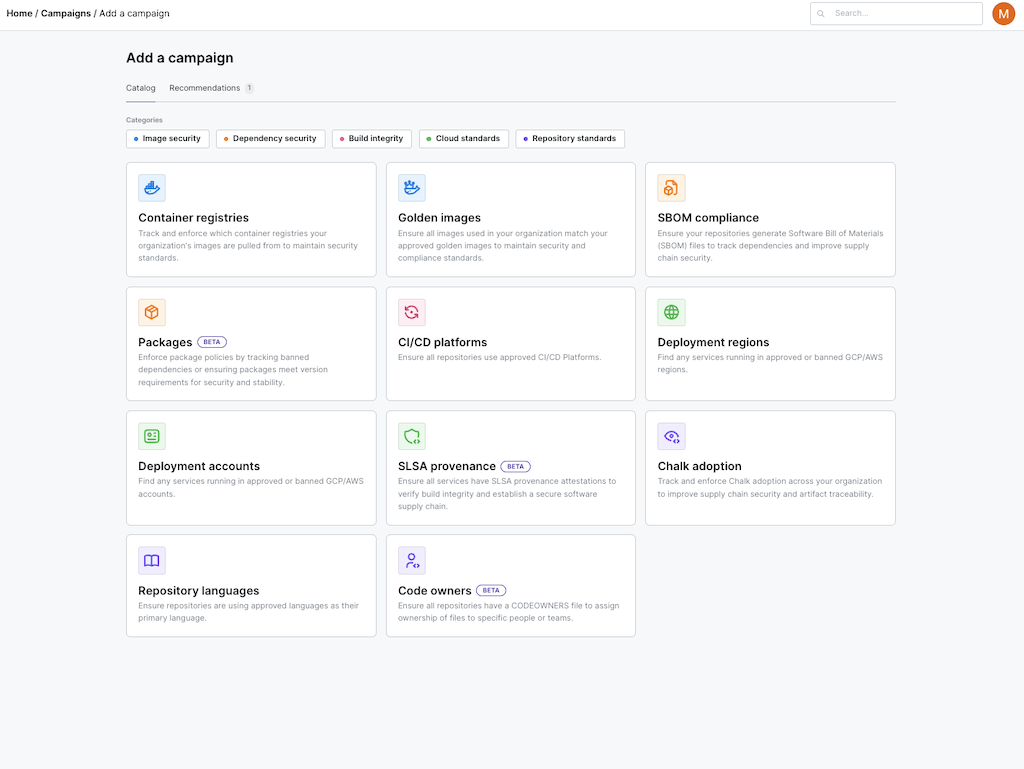
Tomorrow our solutions engineers are going to do a product walkthrough of using the campaigns feature to find shadow container registries and migrate to a central one. It's the most efficient first step an org to migrate to gold images, also a campaign.
If you want your engineering teams to be more effective, ship faster, save money, and improve security, give us a chance to show you what we can do.
https://crashoverride.com/vip-tour
By the way you will keep hearing me say that problems are two sides of the same coin for security and software engineering. I have realized this is a subtle but important thing. Security and development have the same end goal for so many things, that they are starting to tackle them as one. Security is finally being fully owned by development for instance. I think this warrants an article of its own, as it's something I have been waiting to see for 25 years, frankly gave up on, but seems to be finally happening.


