Run containers to browse Chalk data locally
Use prebuilt containers to set up Chalk API server and database server to receive Chalk data
Summary
Chalk is capable of adding all the information you want to collect directly into the artifact. However, this may not always be desirable as certain data, such as SBOM or SAST reports, can be very large. In these cases we recommend capturing the data at build-time and sending it off to the Chalk API server. Soon, you will be able to send this data to Crash Override if you choose, but for the time being, you can run your own by running the API server container and the database server container locally.
We've put together a simple Python-based API Server that will accept reports and chalk marks the chalk binary as it runs, and stick things in an SQLite database. Most of the configuration files used in the how-to guides will set up the chalk binary to automatically push data to the local reporting server, so there is not an extra step during chalk configuration.
- Run the Chalk API server container
- Run the SQLite database container
Steps
Before you start
You will need docker, as the reporting web service will be installed by running two docker containers: one for collecting logs, and the other to give us a web frontend to browse them.
Step 1
To run the Chalk API server container:
docker run -d -w /db -v $HOME/.local/c0/:/db -p 8585:8585 --restart unless-stopped ghcr.io/crashappsec/chalk-test-serverThis will set up an API server on port 8585 on your machine, accessible from any interface. (Note that it will run in the background.)
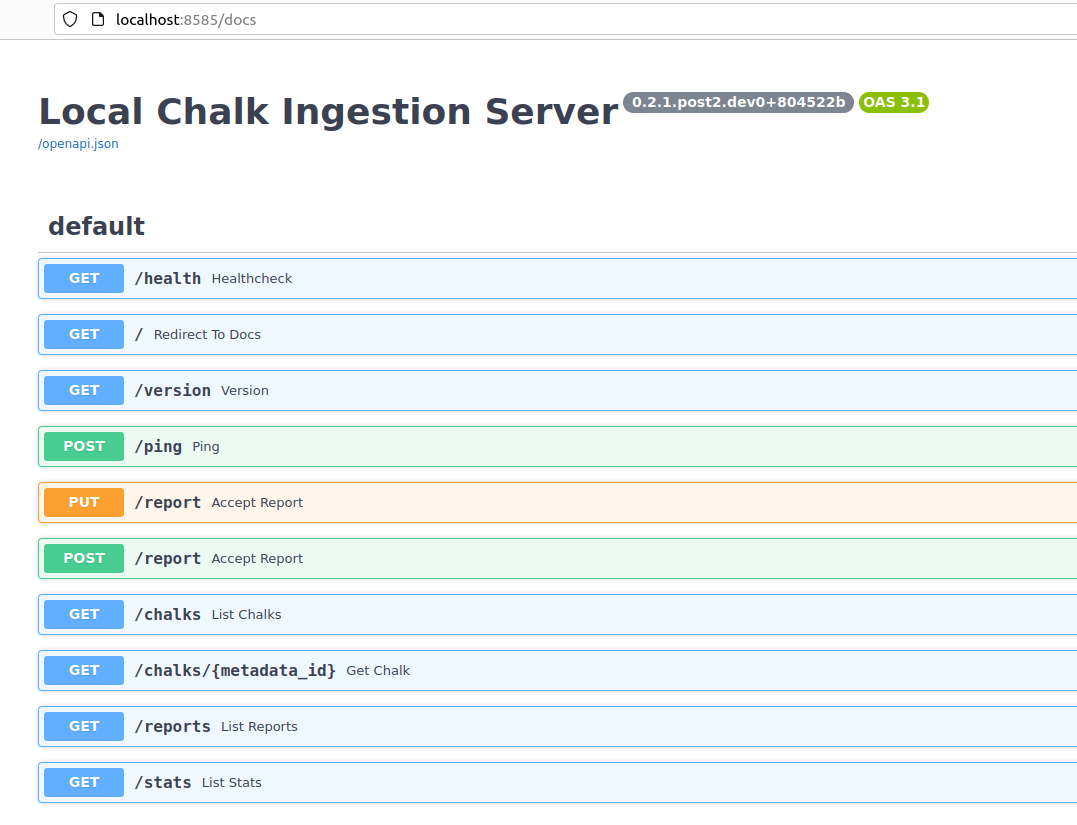
At http://localhost:8585, you should see:
To verify that the API server is healthy, you can run:
curl localhost:8585/healthYou should see the response {"status":"ok"}.
To view the full API documentation, take a look at http://localhost:8585/docs#/.
Step 2
To run the SQLite database container:
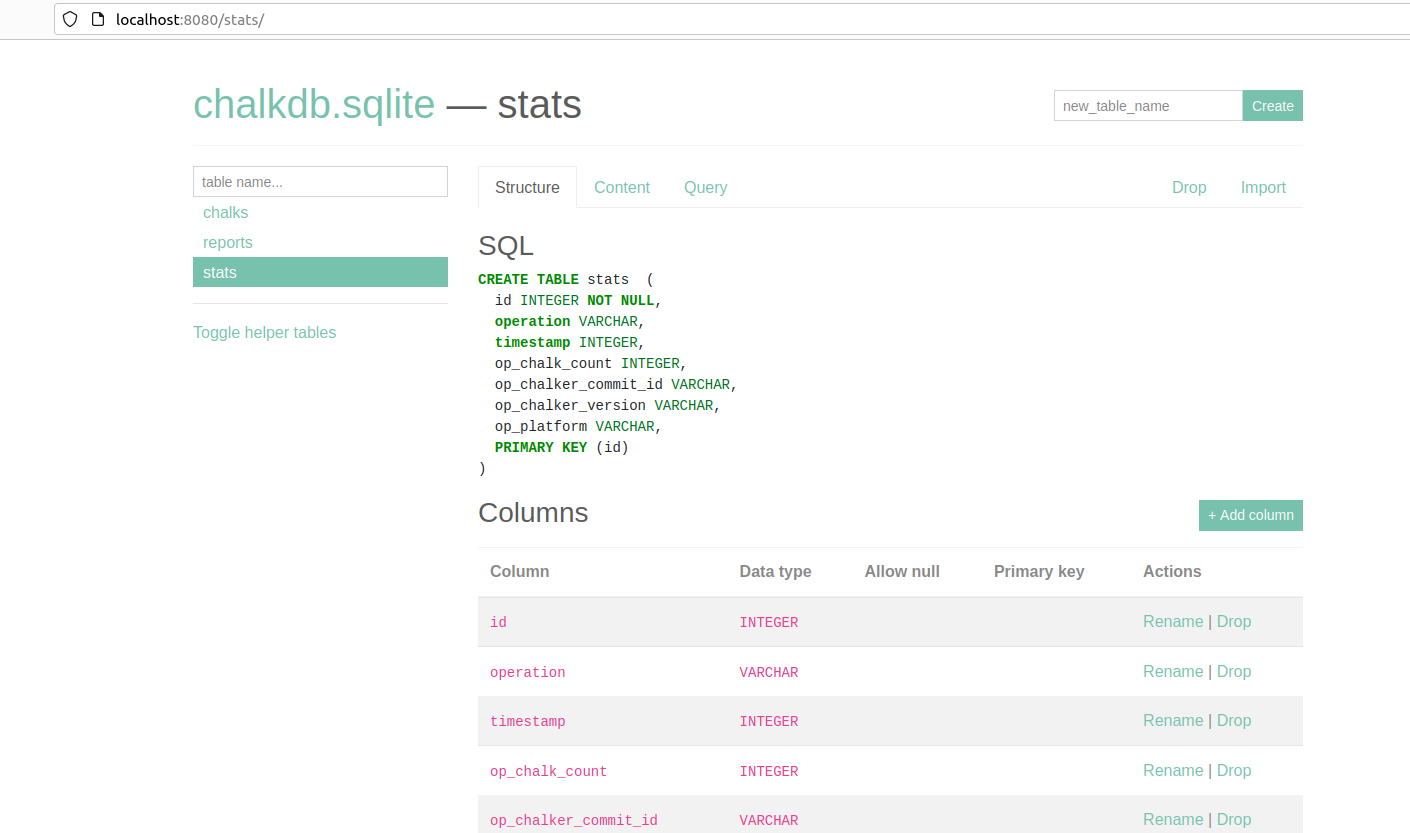
docker run -d -p 8080:8080 -v $HOME/.local/c0/chalkdb.sqlite:/chalkdb.sqlite -e SQLITE_DATABASE=/chalkdb.sqlite coleifer/sqlite-webThe SQLite database will be stored in ~/.local/c0/chalkdb.sqlite:/chalkdb.sqlite.
The database GUI will run on port 8080. At http://localhost:8080, you should see: